|
I am a principal research scientist at NVIDIA Research. I was previously at Google Research, Brain Team. I work on computer vision and machine learning. I did my PhD at Cornell University and Cornell Tech, where I was advised by Serge Belongie. I did my masters at University California, San Diego and my bachelors at National Taiwan University. I received the Best Student Paper Award for Focal Loss at ICCV 2017. I led the creation of the COCO dataset which received the PAMI Mark Everingham Prize at ICCV 2023 and Koenderink Prize at ECCV 2024. Email / CV / Google Scholar / Twitter |

|
|
I work on computer vision, machine learning, and generative AI. Particularly, I am recently interested in generative AI in 3D. Below are recent and selected publications. |
|
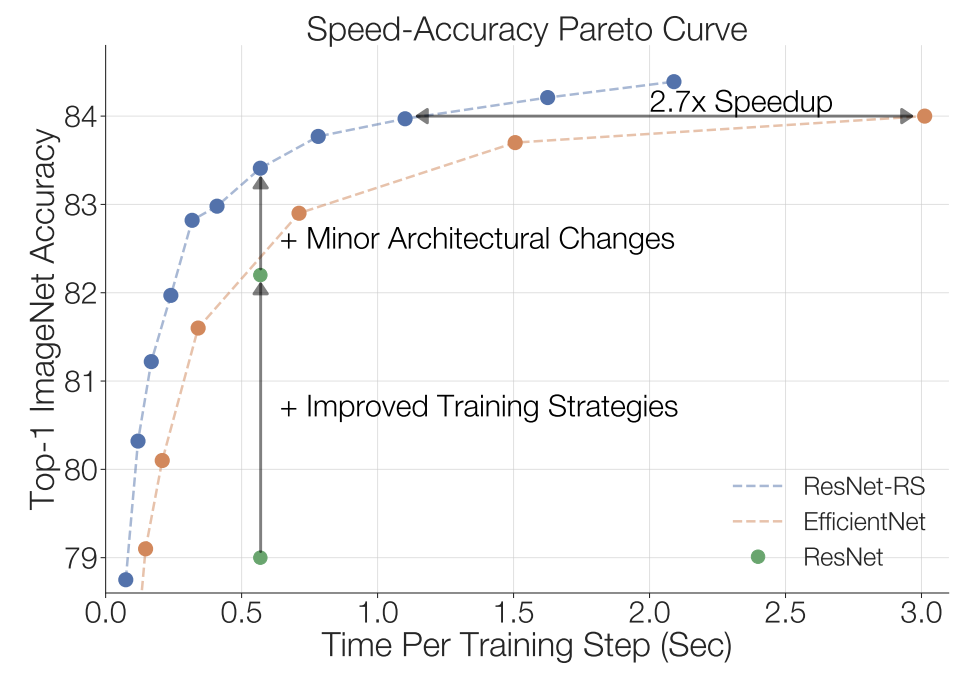
Irwan Bello, William Fedus, Xianzhi Du, Ekin Dogus Cubuk, Aravind Srinivas, Tsung-Yi Lin, Jonathon Shlens, Barret Zoph NeurIPS, 2021 (spotlight) Revisit ResNets with modern scaling and training strategies, showing ResNets are still competitive against modern model architectures. |
|
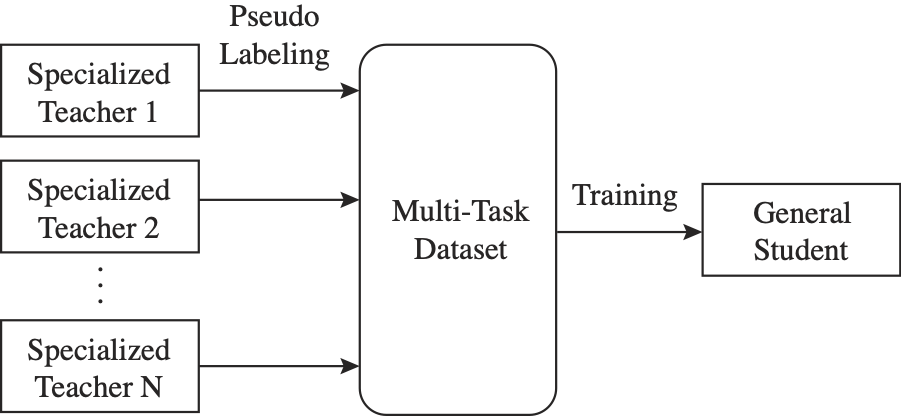
Golnaz Ghiasi*, Barret Zoph*, Ekin Dogus Cubuk*, Quoc V. Le, Tsung-Yi Lin, ICCV, 2021 Apply pseudo labeling to Harness knowledge in multiple datasets/tasks to train one general vision model, achieving competitive results to SoTA on PASCAL, ADE20K, and NYUv2. |
|
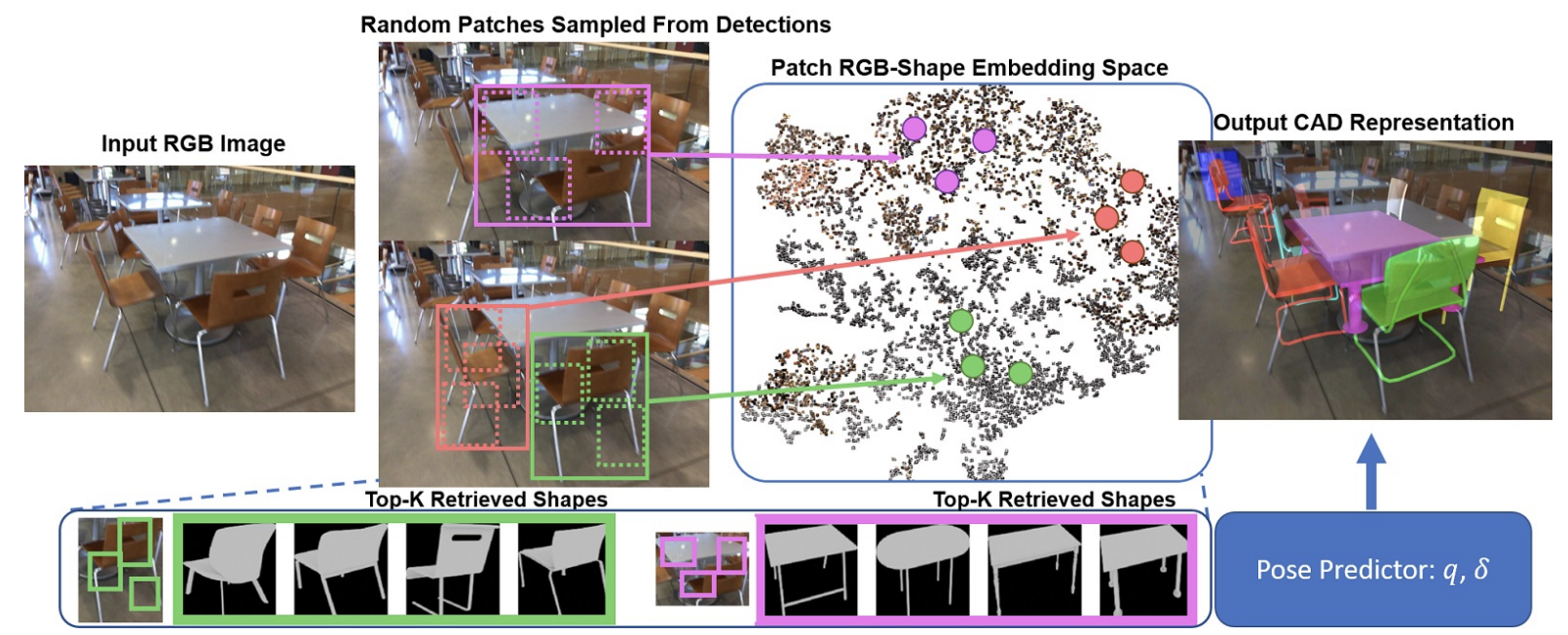
Weicheng Kuo, Anelia Angelova, Tsung-Yi Lin, Angela Dai ICCV, 2021 Learning a patch-based image-CAD embedding space for retrieval based 3D reconstruction, improving upon our prior work Mask2CAD. |

|
Lin Yen-Chen, Pete Florence, Jonathan T. Barron, Alberto Rodriguez, Phillip Isola, Tsung-Yi Lin, IROS, 2021 project page / arXiv / video Given an image of an object and a NeRF of that object, you can estimate that object's pose. |
|
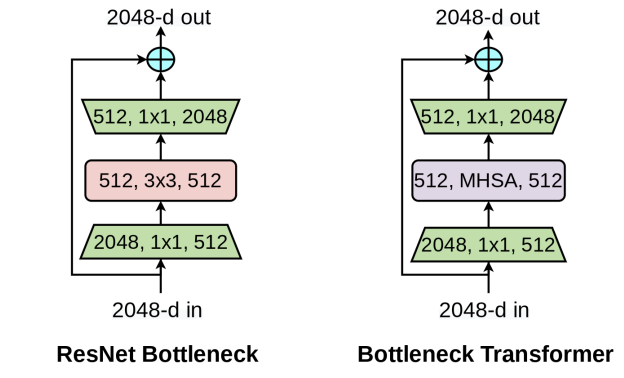
Aravind Srinivas, Tsung-Yi Lin, Niki Parmar, Jonathon Shlens, Pieter Abbeel, Ashish Vaswani CVPR, 2021 Explore a hybrid architecture of CNN and transformer by simply replacing spatial convolutions with self-attention in the final three bottleneck blocks. |

|
Golnaz Ghiasi, Yin Cui, Aravind Srinivas, Rui Qian, Tsung-Yi Lin, Ekin Dogus Cubuk, Quoc V. Le, Barret Zoph CVPR, 2021 (oral) Study copy-paste augmentation for instance segmentation and demonstrating SoTA performance on COCO and LVIS datasets. |
|
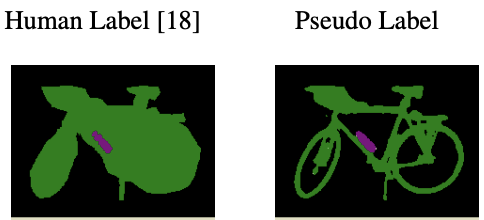
Barret Zoph* Golnaz Ghiasi*, Tsung-Yi Lin*, Yin Cui, Hanxiao Liu, Ekin Dogus Cubuk, Quoc V. Le NeurIPS, 2020 (oral) Compare self-training and pre-training and observe self-training can still improve when pre-training hurts in a region with more labeled data . |

|
Lin Yen-Chen, Andy Zeng, Shuran Song Phillip Isola, Tsung-Yi Lin ICRA, 2020 Blog / Video Leverage visual pre-training from passive observations to aid fast trail-and-error robot learning. Can learn to pick up new objects in ~10 mins. |

|
Weicheng Kuo, Anelia Angelova, Tsung-Yi Lin, Angela Dai ECCV, 2020 (spotlight) Given a single-view image, predict object's 3D shape based on retrieval of CAD models and object pose estimation. |
|
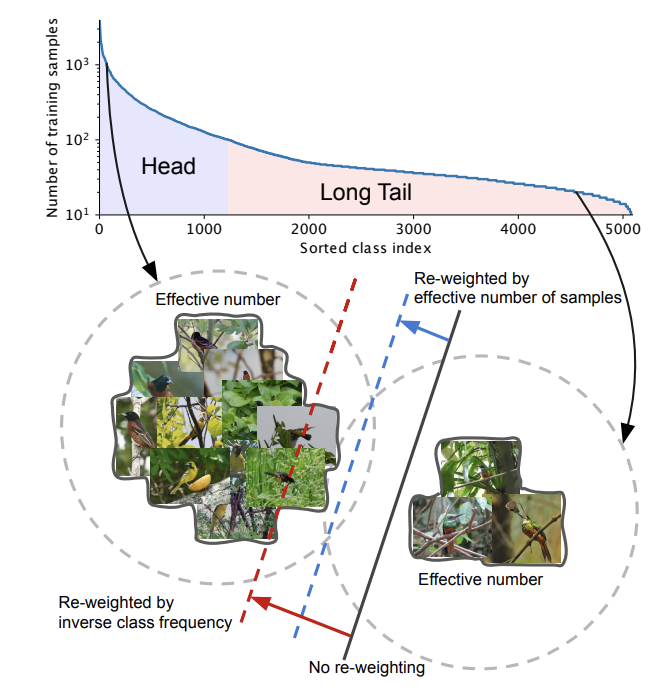
Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song Serge Belongie CVPR, 2019 Propose a benchmark and a simple yet effective class-balanced loss for long-tailed image classification. |
|
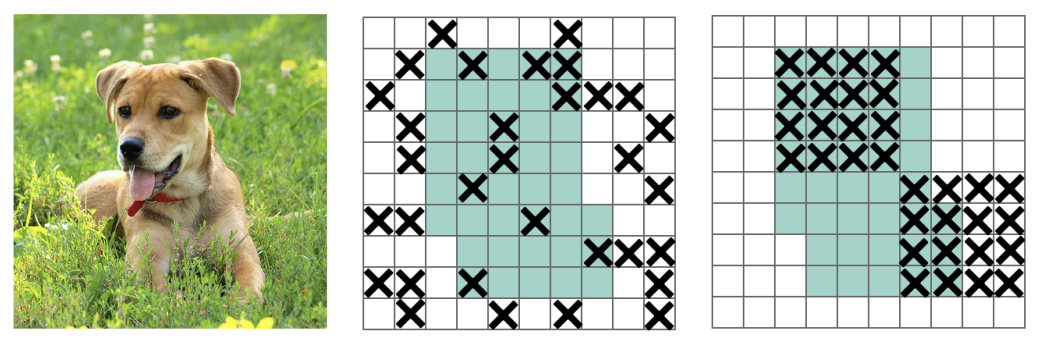
Golnaz Ghiasi, Tsung-Yi Lin, Quoc V. Le NeurIPS, 2018 Drop intermediate features randomly during training to regularize learning, working for image classification, object detection, and semantic segmentation. |
|
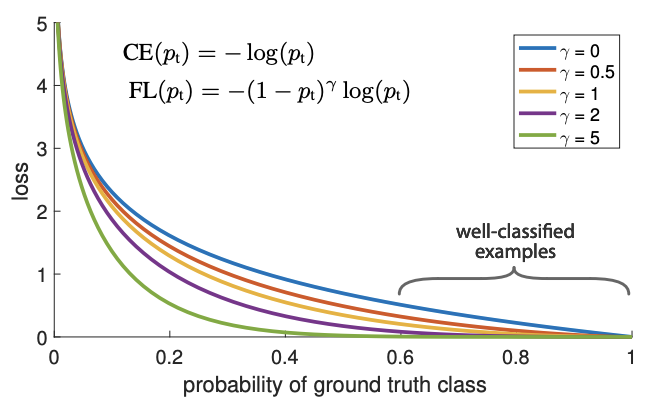
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollar ICCV, 2017 (best student paper award) Propose Focal Loss to address fg/bg imbalanced issue in dense object detection. Focal Loss has been adopted beyond object detection since its invention. |
|
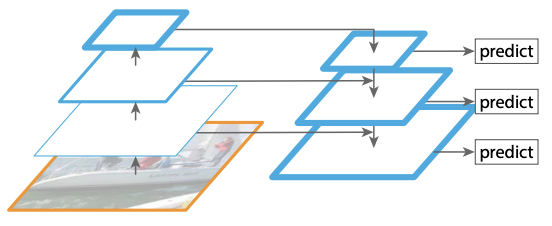
Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie CVPR, 2017 Implement an efficient deep network to bring back the idea of pyramidal representations for object detection. |
|
|
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, Larry Zitnick, Piotr Dollar ECCV, 2014 (oral) Collecting instance segmentation masks of 80 common objects for training object detection models. The dataset was then extended for panoptic segmentation, multi-modal image-text learning, and beyond. |
 |
Area Chair, ICCV 2021
Area Chair, CVPR 2021 |
|
|